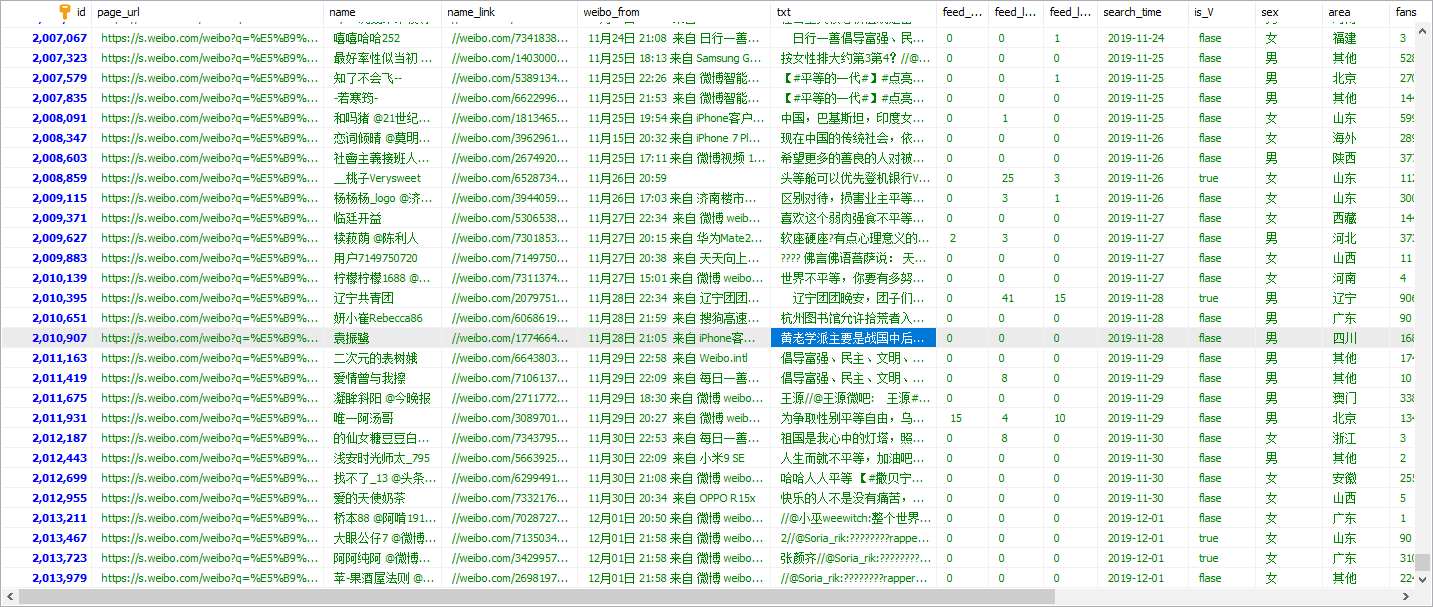
这是一个简单的微博数据爬取的需求,项目起了一个文件夹下,先阅读次部分内容再看文件夹,共采集了250万的数据量。2G的存储。
需求
爬取某个关键字和平在微博特定时间段的2008年-2019年的所有相关的微博。所需字段包含微博内容、点赞数、喜欢数、评论数、发表时间、用户信息、昵称、性别、签名、是否认证、粉丝数、关注数、微博数
分析
在微博的高级搜索里面有根据地区、时间段、特定词搜索结果。
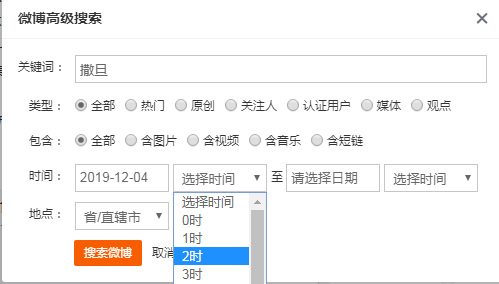
这里可以按照每天的时间过滤。如果需要时间可以再按照具体的小时划分。
用户信息可通过一个好用的api解析。免cookie
设计的方式:生产者消费者模式。将所有的需求设置成任务存贮在数据库。由于爬取的过程中可能出现不稳定因素。所以不建议使用一次性爬取。将所有的任务打上flag标签。
定义线程在100个左右。200万的数据4个小时就爬取完毕。
出错后根据flag再次针对出错的进行爬取。
这种方式的好处。能实时检测到爬虫运行的状态:未爬取、成功、失败、进度。
coding
- 生产者消费者模式
- pyquery
- sqlalchemy
- mysql锁
运行方式
- mysql数据库
- python3.6
安装python库
1 | pip install -r requirements.txt -i https://pypi.douban.com/simple |
配置config.py
1 | 更改mysql数据库ip账号密码 |
创建数据库字段1
python3 model.py
创建任务 create_task.py
1 | 配置cookie |
运行
1 | python3 search_by_db.py |
结果展示